
Services






AI Solutions

An engineer in the bottom of my heart. On the continuous quest for finding a common language between the business and the technology. Used to dress in white or black, today I find myself better in-between, in gray hues. Fascinated about mental models, psychology, communication, learning (and teaching) and software architecture. I hope to never stop asking the "why?" question.
Usually, we think about the code and artefacts connected with it (like documentation, releases, pipelines) as an individual entity. A subtle connection between code and people isn’t apparent at the first glance and can be easily overlooked. Meanwhile, we should perceive those two things which constitute a digital product as a single bio-technological organism. Why is it valuable to think in that way? Why don’t we deliberate about such subtleties when we look at material products like a rake or a mug?
That’s due to one crucial attribute of software products - the ability to be shaped in another way. This adaptability opens a wide array of new possibilities and often it is a decisive point in winning or losing a market. We usually take it for granted that code can be reprogrammed, but actually keeping that perspective available is an ongoing endeavour and definitely, it’s not free. We can be perfectly ok with a rake which can’t adapt to the seasons, but having a digital product which has a fixed-forever set of features is unacceptable these days. This issue is often encountered in the post-MVP phase (you can read about it here) and next to technical debt is a common challenge that needs to be faced.
So what’s the connection between that adaptability and the human perspective? At the end of the day, a product is modified by people. Visual changes in the code or the design, are only materialized artefacts of internalized models. In order to change something, one needs to “decode” a model from code, internalize it, understand it, and then think about how it can be tweaked to support new requirements, and finally “encode” it back.
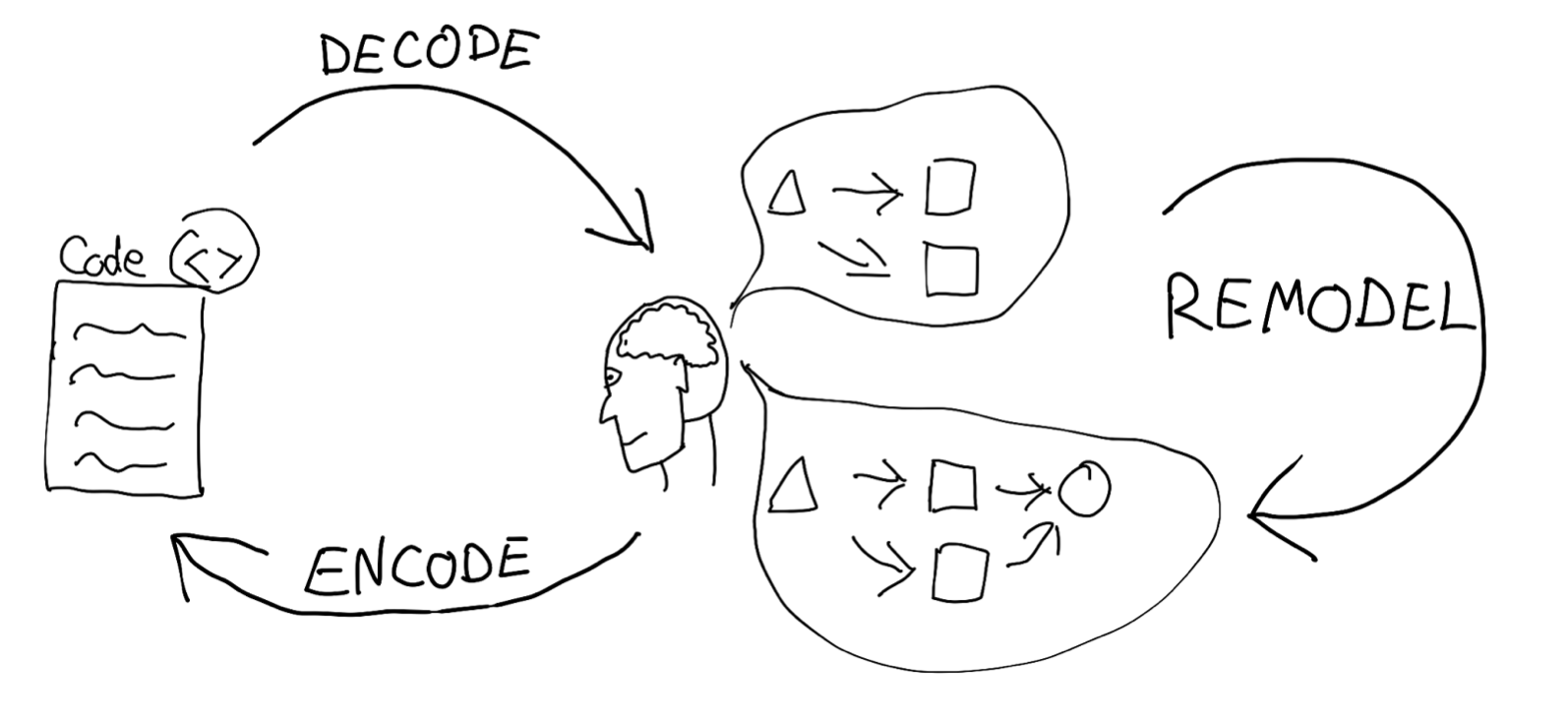
Nevertheless, humans are not computers. We have some limits within which we operate. Those limits are often described as cognitive load. And we can apply that term to the size of models with which we can operate efficiently, but also in terms of the number of personal relationships which we can keep healthy.
That leads us to the term called Dunbar’s number. It indicates how many relationships one can preserve. That number varies depending on the proximity of those relationships, but the most interesting for us is the number 15, which constitutes the Circle of deep trust. Why is it so important? Because it indicates to us the optimal size of a typical product team - which is usually around 8-10 people. The team states a peer-to-peer network, adding more and more “nodes” to it, makes things really hard.
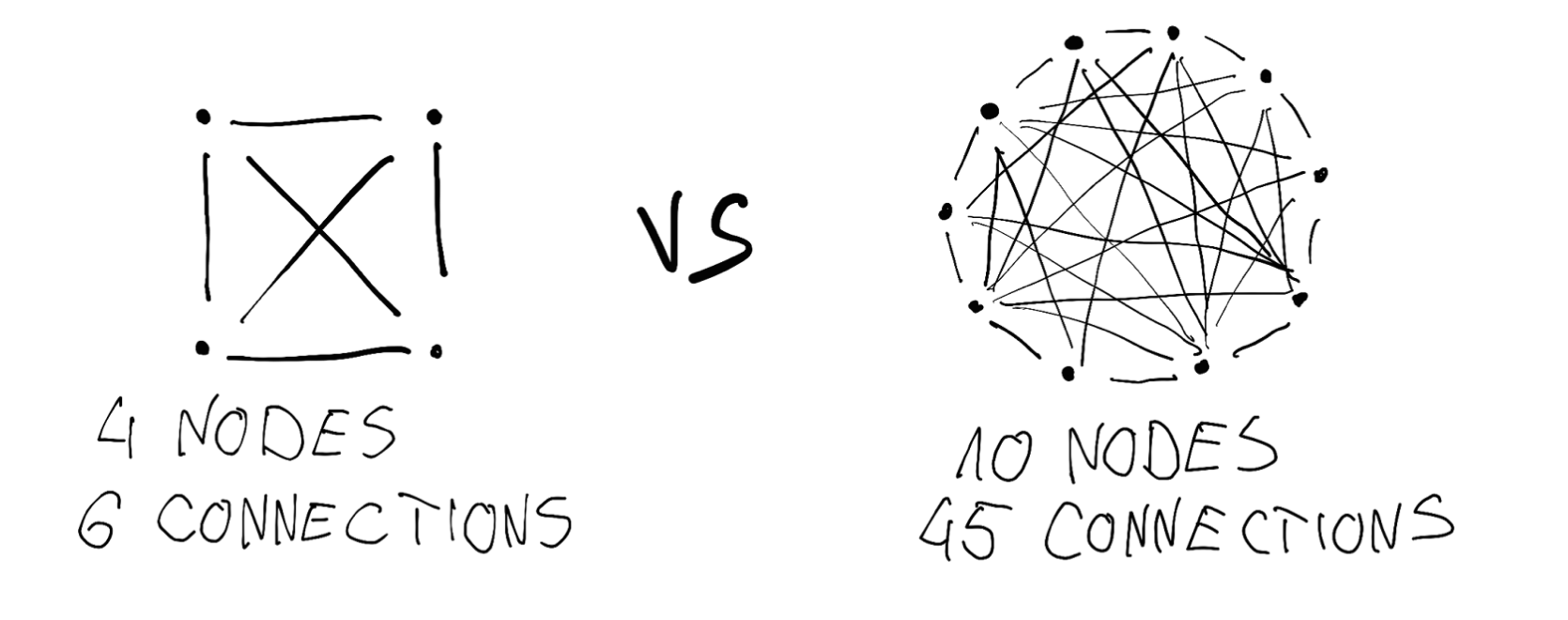
That’s why it is really crucial to pay attention to the signs of that communication overload. There is a natural equilibrium point beyond which, increasing team structure size exposes us heavily to the law of diminishing returns. In most cases making 10+ people teams is impractical and should be avoided. Generally, the smaller team is, the less we suffer from communication problems.
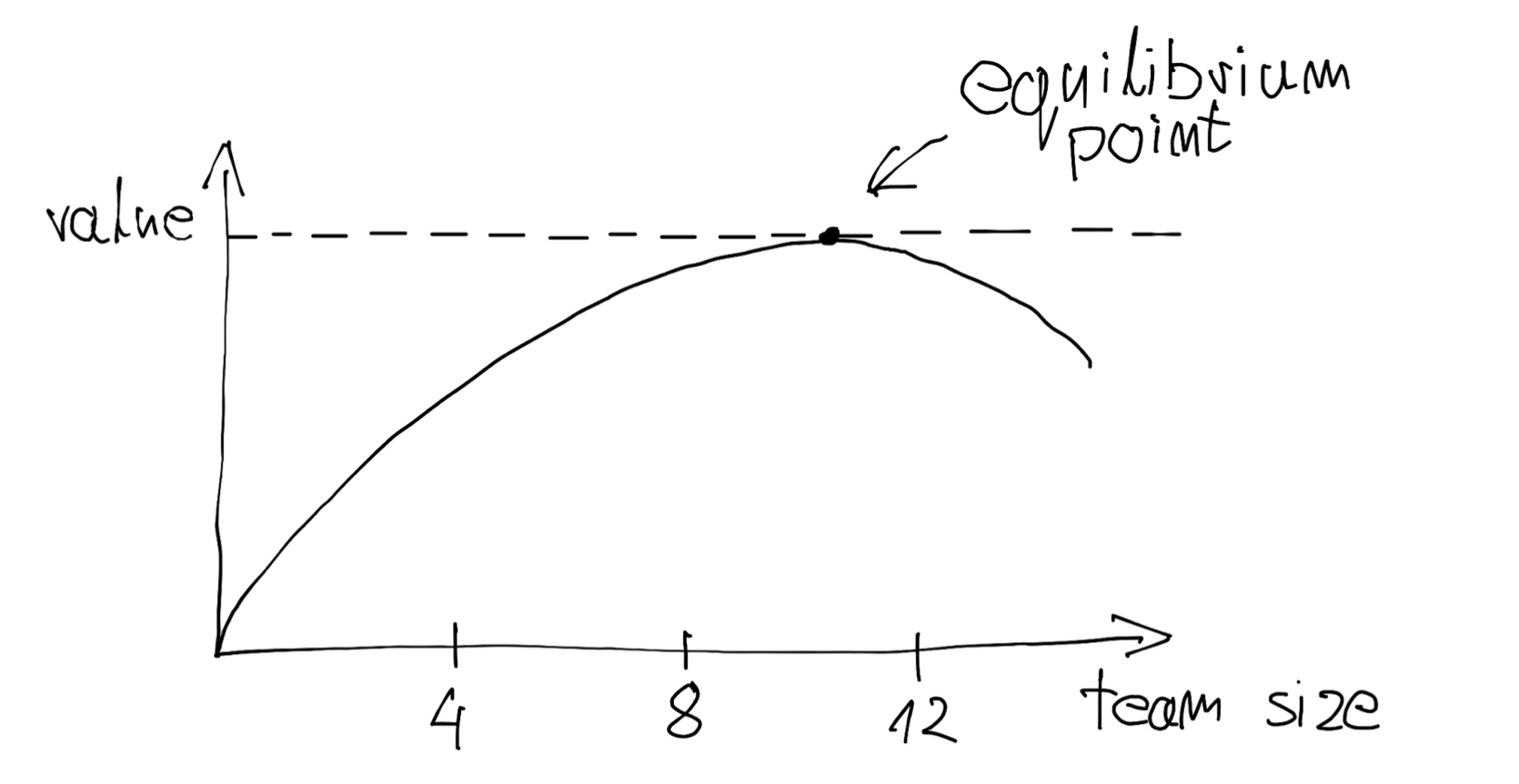
But it’s really hard to imagine those huge and ambitious products are supported by only 10 people. And that leads us to…
Probably, when you were reading the previous paragraph, you came to the natural conclusion about team structure - “We should then create two smaller teams instead of one big”. As we have hard constraints on human mental capacity, then we probably should move a slider with the label “number of teams”.
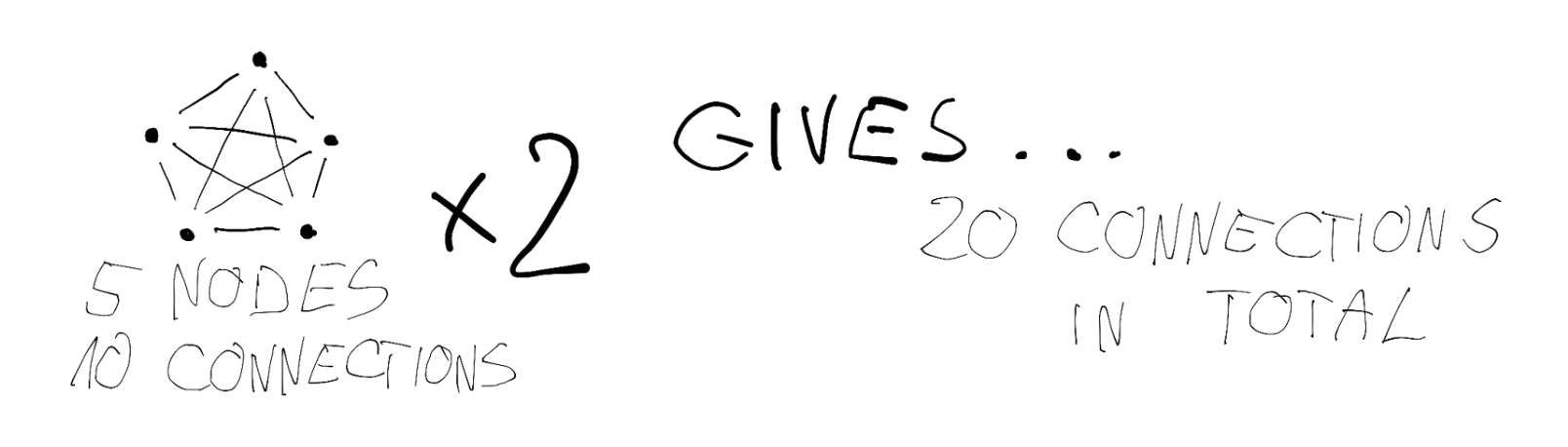
It is one of those things about team topologies, which are simple but not easy. Facing that process implies several ramifications. The first scope of work needs to be divided somehow. If we hope to allow teams to achieve their full potential, we should aim to maximise their autonomy. That’s one of the tenets defining an agile team, it should be capable of delivering a stream of value independently through the whole stack. From discovery, design, development, and testing to maintaining it on the production. Being constantly blocked by the members of other teams violates the autonomy principle, cripples development and is devastating for the team morale.
There is another really interesting hue of dividing the work. It is associated with that internalised way of modelling code mentioned earlier in the article. Really often Conway’s Law comes into play. It says that organizations design systems that mirror their own communication structure. So we can conclude that, if previously there was only one team which was working on some system, they created an architecture optimized for the way they work.
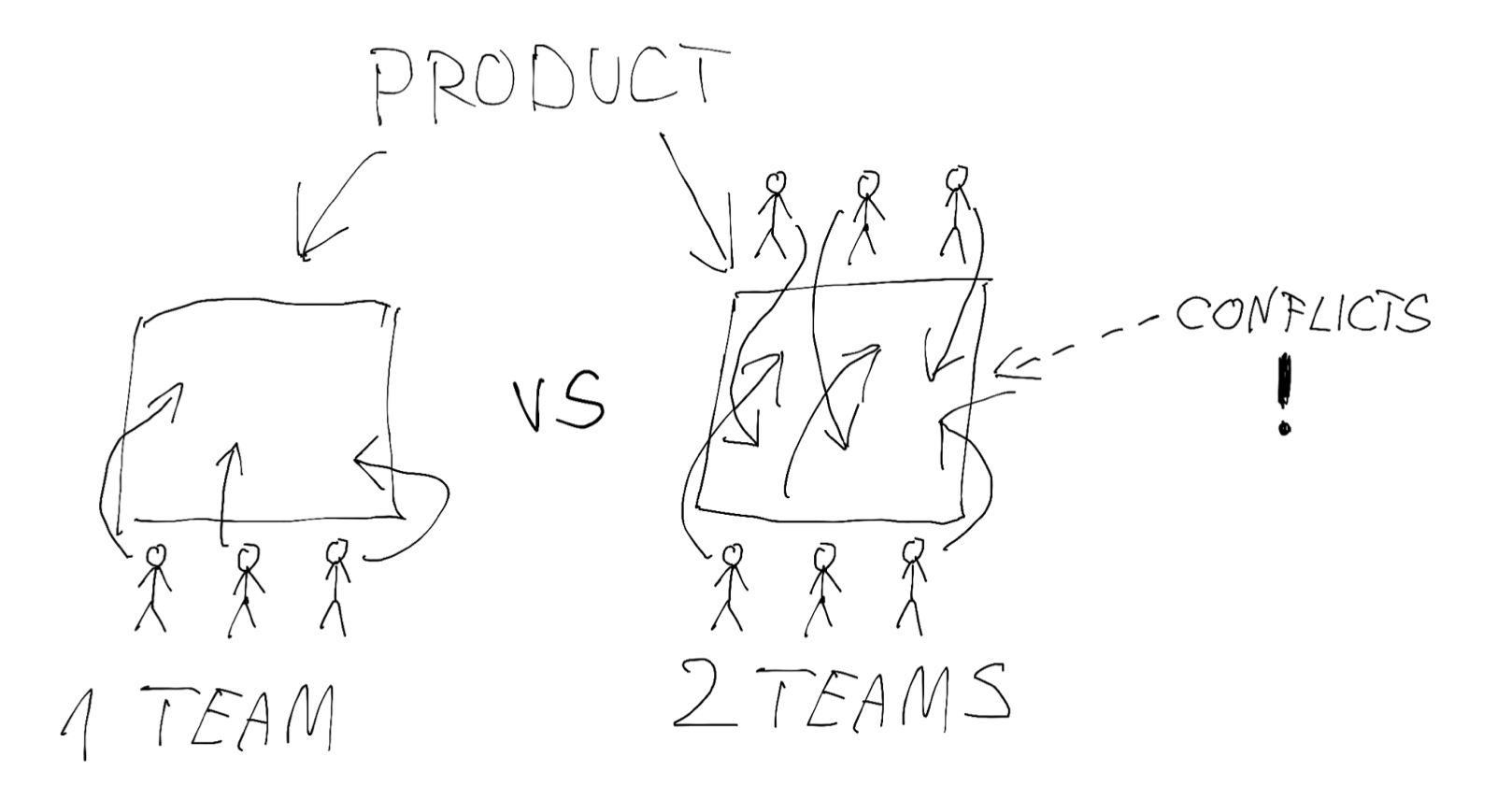
The fact that we decided to split a bigger team into 2 smaller ones, doesn’t automatically split our product into sub-products nor the underlying code or the architecture. And that can be problematic, because instead of being “enabled” folks in those teams will be struggling with the ecosystem. At first, their productivity will suffer from the team reconstitution process - after each change of team member, the team needs some time to “regel”. But moreover, changing team topologies has changed communications patterns. It’s a very important thing to remember when comes to team topologies - they need some space to adjust the reality with which they cope everyday, to those new patterns.
But in the simpler words. If previously, they were working on a big monolithic application with collective ownership, they need to decide if they want to keep an architecture that way and just create a “softer” internal boundaries of ownership, with a joint release cycle. Or maybe the architectural drivers for those 2 parts of the product are incompatible to such an extent that it is beneficial to introduce a hard split, and spawning fully independent service.
I hope this article gave you some clue about what team topologies are and what are the most common obstacles when comes to creating team structures. Generally speaking, it’s heavily context dependent, and basically, throughout the above paragraphs, we were raising the sentence “it depends” to the power of infinity.

